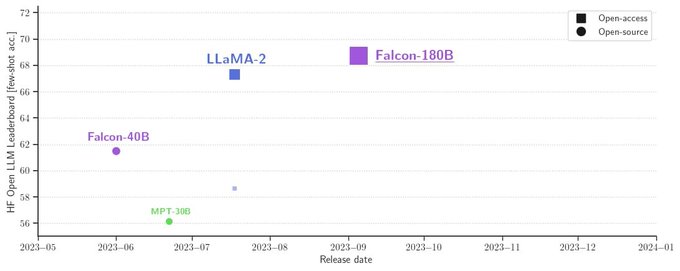
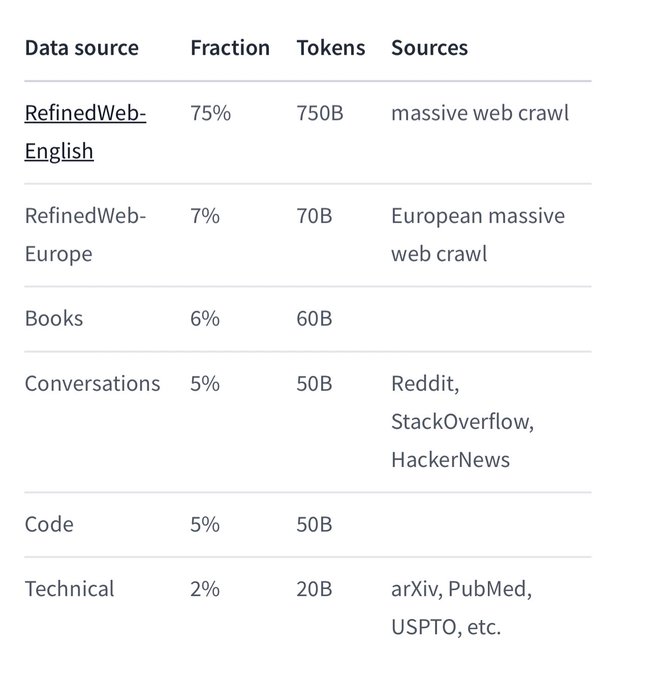
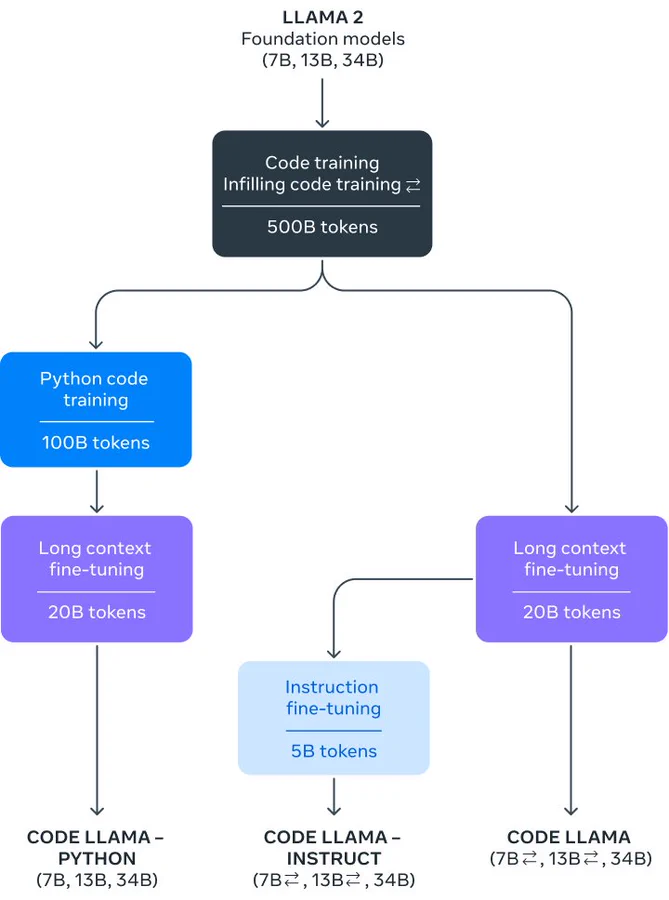
In the ever-evolving landscape of technology, the demand for user-friendly solutions has led to groundbreaking innovations. One such innovation that has captured the imagination of tech enthusiasts and professionals is MetaGPT, a no-code application that empowers users to create web applications effortlessly using natural language. We’ll delve into the incredible capabilities of MetaGPT, explore its applications in data science and analytics, and understand how it streamlines the development process.
The Power of MetaGPT
Understanding the Basics
MetaGPT is a project that aims to build software company one line of input, using a multi-agent framework powered by large language models (LLMs). The beauty of MetaGPT lies in its simplicity – users can achieve all this without writing a single line of code.

Customization at Your Fingertips
One of MetaGPT’s standout features is the ability to customize the application’s interface. This means you can mold the design to suit your specific requirements. Whether you’re a data scientist, an entrepreneur, or a developer, MetaGPT provides a seamless platform to bring your ideas to life.
A Helping Hand from Within
MetaGPT isn’t just a solitary tool; it functions as an entire team of experts. Inside, you’ll find product managers, architects, project managers, and engineers working in harmony. It offers a holistic approach to the software development process, complete with meticulously orchestrated Standard Operating Procedures (SOPs).
The Core Philosophy
At the heart of MetaGPT’s approach is the concept of Code = SOP(Team). This philosophy drives its operations, ensuring that the SOPs are realized and applied to teams composed of Language Model Managers (LLMs). In essence, MetaGPT mirrors the workings of a software company, featuring roles that are based on LLMs.
A Multi-Role Schematic
To grasp the full scope of MetaGPT, it’s crucial to understand the various roles it embodies within a software company. These roles range from product management to architecture, project management, and engineering. As MetaGPT gradually implements these roles, it streamlines the development process for different applications and industries.
MetaGPT’s Abilities in Action
A Visual Showcase
MetaGPT’s capabilities are best exemplified through practical examples. Here’s a glimpse of what it can do:
Example 1: Generating Data and API Designs
Suppose you input a requirement like “Design a RecSys like Toutiao” into MetaGPT. In response, you’d receive a variety of outputs, one of which could be detailed data and API designs.
Jinri Toutiao Recsys Data & API Design
This process is not only efficient but also cost-effective, with an approximate cost of $0.2 in GPT-4 API fees to generate a single example with analysis and design, and around $2.0 for a full project.
Installation Made Easy
MetaGPT has made installation as simple as possible. Here’s a step-by-step guide to get you started:
Traditional Installation
Step 1: Node.js and mermaid-js
- Make sure you have Node.js installed on your system.
- Install mermaid-js using the following command:
shellCopy code
npm install -g @mermaid-js/mermaid-cli
Step 2: Python 3.9+
- Ensure you have Python 3.9+ installed on your system.
Step 3: Cloning and Installation
- Clone the MetaGPT repository to your local machine:
shellCopy code
git clone https://github.com/geekan/metagpt cd metagpt pip install -e.
Please note that if you encounter any issues, try running the installation with the --user flag to avoid permission errors.
Alternative Installation Methods
For converting Mermaid charts to SVG, PNG, and PDF formats, you have various options:
- Playwright: Install Playwright and required browsers, such as Chromium, for PDF conversion.
- pyppeteer: Install pyppeteer, which allows you to use your installed browsers.
- mermaid.ink: A different approach to Mermaid chart conversion.
Conclusion
MetaGPT represents a groundbreaking leap in web application development. Its no-code, natural language interface simplifies the development process, while its extensive capabilities cater to a wide range of users, from data scientists to entrepreneurs. With MetaGPT, you can harness the power of GPT-4 to create web applications that fit your vision. This technology provides an intuitive way for anyone to bring their ideas to life without needing coding expertise.
Yet MetaGPT is just the beginning of what will be possible as AI assistants grow more advanced. We are only scratching the surface of how AI agents can work synergistically with humans to increase productivity and creativity. As natural language AI systems become more conversational and context-aware, we can expect tools like MetaGPT to become even more versatile and responsive to individual needs. The democratization of app development is a precursor to the democratization of many professional skills by increasingly capable AI. MetaGPT provides a glimpse into a future where we will be able to achieve exponentially more with the help of AI agents collaborating as our co-pilots.
FAQs
- Is MetaGPT suitable for beginners in web development?Yes, MetaGPT is designed to be user-friendly and does not require coding skills, making it accessible for beginners.
- Can MetaGPT be used for complex web applications?Absolutely. MetaGPT’s capabilities extend to a wide range of applications, from simple to complex.
- What programming languages does MetaGPT support?MetaGPT is language-agnostic and can generate code for multiple programming languages, catering to diverse needs.
- Is MetaGPT suitable for collaborative projects?Yes, MetaGPT promotes cross-team collaboration by streamlining the development process and providing a common platform for communication.
- Are there any restrictions on the types of web applications MetaGPT can create?MetaGPT is highly versatile and adaptable. It can be used to create a wide variety of web applications, with customization options to suit different requirements.
All in all, MetaGPT is a game-changer for web application development, bridging the gap between code and creativity. Whether you’re a seasoned developer or a newcomer to the field, this innovative tool has the potential to revolutionize the way you approach web app development.