Stability AI has unveiled its latest breakthrough in AI-generated 3D imagery – Stable Zero123. This new model sets a new high bar for creating photorealistic 3D renderings of objects from a single input image.
Introducing Stable Zero123: Quality 3D object generation from single images.
Stable Zero123, a new in-house generative AI model is capable of creating 3D objects from any input image.
Due to improved training datasets and elevation conditioning, the model demonstrates 3D… pic.twitter.com/JGCigD3f7a
Stable Zero123 leverages three key innovations to achieve superior image quality compared to previous state-of-the-art models like Zero123-XL. First, the team curated a high-quality dataset from Objaverse, filtering out low-quality 3D objects and re-rendering the remaining objects with enhanced realism. Second, the model is provided with estimated camera angle data during training and inference, allowing it to generate images with greater precision. Finally, optimizations like pre-computed latents and an improved dataloader enabled much more efficient training, with a 40X speed-up over Zero123-XL.
Early tests show Stable Zero123 generates remarkably vivid and consistent 3D renderings across various object categories. Its ability to extrapolate realistic 3D structure from limited 2D image cues highlights the rapid progress in this blossoming field. With further advancements, AI-assisted 3D model creation could soon become indispensable across industries like gaming, VR, and 3D printing.
Enhanced Training Dataset
The Enhanced Training Dataset for the Stable Zero123 model is based on renders from the Objaverse dataset, utilizing an enhanced rendering method. The model is a latent diffusion model and was trained on the Stability AI cluster on a single node with 8 A100 80GBs GPUs. The training dataset and infrastructure used are specific to the development of the Stable Zero123 model.
Applications and Impact
The enhancements unveiled in Stable Zero123 could have wide-ranging impacts across several industries that rely on 3D digital content. Sectors like gaming and VR are constantly pushing the boundaries of realism in asset creation, and Stable Zero123’s ability to extrapolate intricate 3D models from basic 2D sketches could significantly accelerate development timelines. More consumer-focused applications like 3D printing may also benefit, as users can quickly iterate through design ideas without intensive modeling expertise.
Perhaps most promising is Stable Zero123’s potential to democratize advanced 3D creation capabilities. While photorealistic CGI rendering currently requires specialized skills and tools, Stable Zero123 provides a glimpse of more automated workflows. If ongoing research continues to enhance these generative AI systems, nearly anyone may soon possess the powers of professional 3D artists at their fingertips. Brand-new creative possibilities could emerge when designers and artists of all skill levels can experiment rapidly with 3D concepts that once seemed unattainable. In the near future, Stable Zero123’s innovations could unlock newfound productivity and imagination across industries.
Conclusion
With the launch of Stable Zero123, Stability AI continues its relentless pace of innovation in AI-generated media. Coming on the heels of breakthroughs like Stable Diffusion for image generation and Stable Diffusion Video for text-to-video creation, Stability AI is establishing itself as a leading force in this rapidly evolving landscape. Stable Zero123 delivers their most impressive achievement yet in photorealistic 3D model generation from limited 2D inputs.
The enhancements in data curation, elevation conditioning, and training efficiency have enabled unprecedented image quality leaps over previous state-of-the-art models. As Stability AI continues to push boundaries, applications spanning gaming, VR, 3D printing, and more may see transformative productivity gains from AI-assisted content creation. If progress maintains this velocity, the future looks bright for next-generation creative tools that capture imaginations and unlock new possibilities. Stable Zero123 provides a glimpse into this exciting frontier, where AI equips people across skill levels with once-unfathomable 3D creation superpowers. You can check out the weights on Huggingface.
In a move that turned heads and sparked instant debate, open-source model startup Mistral AI released their latest LLM not with a splashy launch event or polished press release, but with a simple tweet containing a single link: a magnet URL for a massive torrent file.
This audacious approach stands in stark contrast to the carefully orchestrated media blitz that accompanied Google’s recent Gemini launch, or the “over-rehearsed professional release video talking about a revolution in AI” that OpenAI’s Andrej Karpathy mocked on social media. While other companies were busy crafting narratives and highlighting their technological prowess, Mistral simply dropped the mic with a torrent link.
The LLM in question, MoE 8x7B, has generated immediate buzz within the AI community. Described by some as a “scaled-down GPT-4,” it’s believed to be a Mixture of Experts model with 8 individual experts, each possessing 7 billion parameters. This architecture mirrors what we know of GPT-4, albeit with significantly fewer parameters.
This bare-bones release, devoid of any formal documentation or promotional materials, is characteristic of Mistral AI. As AI consultant and community leader Uri Eliabayev noted, “Mistral is well-known for this kind of release, without any paper, blog, code or press release.” While some may find this approach unconventional, it has undoubtedly generated a significant amount of attention and speculation. As open source AI advocate Jay Scambler aptly put it, “It’s definitely unusual, but it has generated quite a bit of buzz, which I think is the point.”
Whether this unorthodox approach marks a new era of open-source AI development remains to be seen. However, one thing is certain: Mistral AI has succeeded in capturing the imagination of the AI community, and their enigmatic release has sparked important conversations about transparency, accessibility, and the future of large language models.
Details of the Release
In a tweet Mistral drops a torrent link containing 8x 7B MoE model but, there were no further details.
Mistral AI provided minimal details about the release of MoE 8x7B, opting for a cryptic tweet containing only a torrent link. However, some insights can be gleaned from the limited information available.
Key Takeaways:
Model Parameters: The params.json file reveals several key parameters:
Hidden dimension: 14336 (3.5x expansion)
Dimension: 4096
Number of heads: 32 (4x multiquery)
Number of KV heads: 8
Mixture of Experts (MoE): 8 experts, top 2 used for inference
Related Code: While no official code for MoE 8x7B is available, the GitHub repository for megablocks-public likely contains relevant code related to the model’s architecture.
Noticeably Absent: Unlike many other LLM releases, MoE 8x7B was not accompanied by a polished launch video or press release.
These details suggest that MoE 8x7B is a powerful LLM with a unique architecture. The MoE approach allows for efficient inference by utilizing only the top 2 experts for each token, while still maintaining high performance. The 3.5x expansion of the hidden dimension and 4x multiquery further enhance the model’s capabilities.
The timing of the release, just before the NeurIPS conference, suggests that Mistral AI may be aiming to generate interest and discussion within the AI community. The absence of a traditional launch event is likely intentional, as it aligns with Mistral’s more open-source and community-driven approach.
While the lack of detailed information may leave some wanting more, it also fosters a sense of mystery and excitement. This unorthodox approach has undoubtedly captured the attention of the AI community, and we can expect to see further analysis and experimentation with MoE 8x7B in the coming weeks and months.
Potential Parameters
A JSON file containing parameters for a large language model (LLM) called MoE 8x7B.
The parameters in the JSON file provide some insights into the architecture of MoE 8x7B. The hidden dimension is 14336, which is 3.5 times larger than the dimension of 4096. This suggests that MoE 8x7B is a very powerful LLM with a high degree of complexity.
The number of heads is 32 and the number of KV heads is 8. This indicates that MoE 8x7B uses a multiquery attention mechanism, which allows it to process multiple input sequences simultaneously.
The MoE architecture is a type of Mixture of Experts model, which means that it consists of multiple experts, each specialized to perform a different task. In the case of MoE 8x7B, there are 8 experts. Only the top 2 experts are used for inference, which allows for efficient computing and high performance.
Basically, the parameters in the JSON file suggest that MoE 8x7B is a cutting-edge LLM with a unique architecture. It is still too early to say how well MoE 8x7B will perform on real-world tasks, but it is certainly a promising development in the field of AI.
What could this mean for the future of AI?
The release of MoE 8x7B demonstrates a few important trends in the field of AI:
The increasing importance of open source software. MoE 8x7B is an open-source LLM, which means that anyone can download and use it for free. This is a significant development, as it democratizes access to powerful AI technology.
The rise of new LLM architectures. MoE 8x7B is a Mixture of Experts model, which is a relatively new type of LLM architecture. This suggests that the field of LLM research is still evolving and that there is still significant room for innovation.
The increasing focus on efficiency and performance. MoE 8x7B is designed to be efficient and performant, even when used on resource-constrained devices. This is important for enabling the use of LLMs in real-world applications.
This release of MoE 8x7B is a positive development for the future of AI. It demonstrates the power of open source software, the rise of new LLM architectures, and the increasing focus on efficiency and performance. It is likely that we will see more and more innovative and powerful LLMs being released in the coming years, and MoE 8x7B is a clear example of this trend.
Move over, ChatGPT, there’s a new AI in town, and it’s packing serious heat. Google has officially released Gemini, its latest and most powerful language model, and it’s already powering the beloved Bard chatbot. This marks a significant turning point in the world of AI, with Gemini poised to revolutionize the way we interact with machines and unlock new possibilities for creativity, productivity, and understanding.
Imagine an AI that can effortlessly translate languages, write captivating stories, decode complex code, and answer your most burning questions with insightful accuracy. That’s the promise of Gemini, and it’s a promise that’s finally become reality. This isn’t just another incremental upgrade; it’s a quantum leap forward, pushing the boundaries of what AI can achieve.
So, buckle up and prepare for a thrilling ride as we explore the exciting world of Google’s Gemini and its transformative potential for the future. Get ready to discover how Bard, now fueled by this revolutionary technology, is poised to become the ultimate AI companion, empowering you to unlock your own creativity and achieve the seemingly impossible.
Exploring Gemini
What is Gemini?
Google Gemeni is an AI model developed by Google DeepMind. Gemini is designed for multimodality, allowing it to reason across text, images, video, audio, and code. It has been evaluated on various tasks and has surpassed the performance of previous state-of-the-art models. It is described as the most capable and largest model for highly complex tasks, with the ability to generate code, combine text and images, and reason visually across languages. It is also available in three sizes: Ultra, Pro, and Nano, each suited for different types of tasks. The search result provides a visual and descriptive representation of Gemini’s functionality and invites users to explore its prompting techniques and capabilities further.
Key features and models
Multimodality: Gemini is built from the ground up for multimodality, allowing it to reason seamlessly across text, images, video, audio, and code.
Performance: Gemini has surpassed the state-of-the-art (SOTA) performance on all multimodal tasks, making it one of the most capable AI models available.
Capability Benchmark: Gemini has been evaluated on various benchmarks, including general language understanding, reasoning, reading comprehension, commonsense reasoning, math, code generation, and natural language understanding, among others.
Multimodal Capabilities: Gemini’s multimodal capabilities include representation of questions in various subjects, diverse set of challenging tasks requiring multi-step reasoning, reading comprehension, commonsense reasoning for everyday tasks, math problems, code generation, and natural language understanding, among others.
Different Sizes: Gemini comes in three sizes – Ultra, Pro, and Nano, each catering to different use cases. The Ultra model is the most capable and largest model for highly complex tasks, the Pro model is best for scaling across a wide range of tasks, and the Nano model is the most efficient for on-device tasks.
Native Multimodality: Gemini is natively multimodal, which means it has the potential to transform any type of input into any type of output, making it a versatile and powerful AI model.
Gemini is a highly advanced AI model with unmatched multimodal capabilities, performance, and versatility, making it a significant advancement in the field of artificial intelligence.
Different Sizes
Model
Description
Ultra
Our most capable and largest model for highly-complex tasks.
Pro
Our best model for scaling across a wide range of tasks.
Nano
Our most efficient model for on-device tasks.
Ultra: The most powerful and sophisticated model, designed for highly complex tasks. It serves as the benchmark for our other models and pushes the boundaries of AI performance. As far as we know there is still no official release date yet.
Pro: This versatile model excels at scaling across a broad spectrum of tasks, making it the backbone of Bard. It delivers a powerful AI experience for Bard users today.
Nano: A smaller model that is optimized for mobile use.
Gemini in Action
Benchmarks
Google’s new Gemini AI releases benchmarks The big deal is that it appears to be the first model to beat GPT-4. The fascinating thing is that it does it by just a tiny bit. It is now integrated into Bard now but I haven’t seen an immediate difference. More when I can test it
Testing
For testing I asked Bard a relatively recent Leetcode question, this way we can avoid it being in the training data. I asked it Leetcode question 2859, Sum of Values at Indices With K Set Bits.
Here is the solution it gave me, albeit it was an easy question
Final Thoughts
Google’s release of Bard powered by the conversational AI model Gemini shows their continued commitment to pushing the boundaries of artificial intelligence technology. While there are still open questions around when the more advanced Gemini Ultra could be available and whether it will be free to use, Bard already demonstrates impressive language capabilities.
The launch comes at an interesting time as Google aims to regain some of its reputation as an AI leader after open source libraries like PyTorch, Llama, XGBoost have challenged the dominance of Google’s TensorFlow and Keras. With companies like Anthropic, Meta, and OpenAI also showcasing powerful new AI models recently, the competition in the space keeps heating up.
Ultimately, this increased competition should drive more innovation which is a win for consumers. Google is betting that Bard and the underlying Gemini framework will allow them to deliver more helpful, safe, and grounded AI applications compared to alternatives. While only time will tell if Bard becomes a breakthrough in AI, Google’s willingness to keep pushing boundaries even in a crowded field shows their ambition has not slowed. If Bard lives up to its promise, this launch could mark Google’s comeback as the pacesetter in AI.
Human image animation aims to create realistic videos of people by animating a single reference image. However, existing techniques often struggle with maintaining fidelity to the original image and smooth, consistent motions over time. Enter MagicAnimate – an open source image animation AI that leverages the power of diffusion models to overcome these challenges.
Created by a team of researchers seeking to enhance video generation quality, MagicAnimate incorporates novel techniques to improve temporal consistency, faithfully preserve reference image details, and increase overall animation fidelity. At its core is a video diffusion model that encodes temporal data to boost coherence between frames. This works alongside an appearance encoder that retains intricate features of the source image so identity and quality are not lost. Fusing these pieces enables remarkably smooth extended animations.
Early testing shows tremendous promise – significantly outperforming other methods on benchmarks for human animation. On a collection of TikTok dancing videos, MagicAnimate boosted video fidelity over the top baseline by an impressive 38%! With performance like this on complex real-world footage, it’s clear these open source models could soon revolutionize the creation of AI-generated human animation.
We’ll dive deeper into how MagicAnimate works and analyze the initial results. We’ll also explore what capabilities like this could enable in the years to come as the technology continues to advance.
How MagicAnimate Works
MagicAnimate is a diffusion-based framework designed for human avatar animation with a focus on temporal consistency. It effectively models temporal information to enhance the overall temporal coherence of the animation results. The appearance encoder not only improves single-frame quality but also contributes to enhanced temporal consistency. Additionally, the integration of a video frame fusion technique enables seamless transitions across the animation video. MagicAnimate demonstrates state-of-the-art performance in terms of both single-frame and video quality, and it has robust generalization capabilities, making it applicable to unseen domains and multi-person animation scenarios.
Diagram the MagicAnimate paper, Given a reference image and the target DensePose motion sequence, MagicAnimate employs a video diffusion model and an appearance encoder for temporal modeling and identity preserving, respectively (left panel). To support long video animation, we devise a simple video fusion strategy that produces smooth video transition during inference (right panel).
Comparing to Animate Anyone
MagicAnimate and Animate Anyone both belong to the realm of text-to-image and text-to-video generation, leveraging diffusion models to achieve superior results. However, they exhibit distinctive approaches in their methodologies and applications.
1. Image Generation Backbone:
MagicAnimate: The framework predominantly employs Stable Diffusion as its image generation backbone, emphasizing the generation of 2D optical flow for animation. It utilizes ControlNet to condition the animation process on OpenPose keypoint sequences and adopts CLIP to encode the reference image into a semantic-level text token space, guiding the image generation process through cross-attention.
Animate Anyone: In contrast, Animate Anyone focuses on the diffusion model for image generation and highlights the effectiveness of diffusion-based methods in achieving superior results. It explores various models, such as Latent Diffusion Model, ControlNet, and T2I-Adapter, to strike a balance between effectiveness and efficiency. It delves into controllability by incorporating additional encoding layers for controlled generation under various conditions.
2. Temporal Information Processing:
MagicAnimate: While MagicAnimate produces visually plausible results, it tends to process each video frame independently, potentially neglecting the temporal information in animation videos.
Animate Anyone: Animate Anyone draws inspiration from diffusion models’ success in text-to-image applications and integrates inter-frame attention modeling to enhance temporal information processing. It explores the augmentation of temporal layers for video generation, with approaches like Video LDM and AnimateDiff introducing motion modules and training on large video datasets.
3. Controllability and Image Conditions:
MagicAnimate: MagicAnimate conditions the animation process on OpenPose keypoint sequences and utilizes pretrained image-language models like CLIP for encoding the reference image into a semantic-level text token space, enabling controlled generation.
Animate Anyone: Animate Anyone explores controllability extensively, incorporating additional encoding layers to facilitate controlled generation under various conditions such as pose, mask, edge, depth, and even content specified by a given image prompt. It proposes diffusion-based image editing methods like ObjectStitch and Paint-by-Example under specific image conditions.
While both MagicAnimate and Animate Anyone harness diffusion models for text-to-image and text-to-video generation, they differ in their choice of image generation backbones, their treatment of temporal information, and the extent to which they emphasize controllability and image conditions. MagicAnimate puts a strong emphasis on Stable Diffusion and cross-attention guided by pretrained models, while Animate Anyone explores a broader range of diffusion models and integrates additional encoding layers for enhanced controllability and versatility in image and video generation.
Closing Thoughts
As AI-powered image animation continues advancing rapidly, the applications are becoming increasingly versatile but may also raise ethical concerns. While MagicAnimate demonstrates promising results, generating custom videos of people requires careful consideration.
Compared to recent sensation AnimateAnyone which produced very realistic animations, MagicAnimate does not yet achieve the same level of fidelity. However, the results here still showcase meaningful improvements in consistency and faithfulness to the source.
As the code and models have not yet been opened sourced, the degree to which the demo videos reflect average performance remains unclear. It is common for research to highlight best-case examples, and real-world results vary. As with any machine learning system, MagicAnimate likely handles some examples better than others.
Nonetheless, between AnimateAnyone, MagicAnimate and other recent papers on AI-powered animation, the pace of progress is staggering. It’s only a matter of time before generating hyper-realistic animations of people on demand becomes widely accessible. And while that enables creative new applications, it also poses risks for misuse and mistreatment that could violate ethics or consent.
As this technology matures, maintaining open and thoughtful conversations around implementation will be critical. But with multiple strong approaches now proven, high-quality human animation powered by AI appears inevitable.
Creating life-like character animation from simple still images is an alluring concept and a challenging niche within visual generation research. As we continue to unlock the robust generative capabilities of diffusion models, the door to this fascinating frontier opens wider. Yet, even as we step across the threshold, we find ourselves confronted with persistent hurdles; primarily, the daunting task of maintaining temporal consistency with intricate detailed information from an individual character. Despite the challenges, the potential of this revolutionary technology is undeniable.
This paper explores a revolutionary approach that harnesses the power of diffusion models to animate any character from a static image, ensuring a level of detail and controllability previously unattainable. Herein, we introduce a novel framework, the ReferenceNet, designed to preserve intricate appearance features from the reference image and an innovative pose guider to direct character movements. Paired with an efficient temporal modeling method for seamless inter-frame transitions, the resulting framework promises remarkable progress in character animation. Empirically tested and evaluated on fashion video and human dance synthesis benchmarks, our innovation demonstrates superior results and sets a new precedent for image-to-video methodologies.
Animate Anyone Method
The crux of the method, aptly named ‘Animate Anyone’, is its unique approach that embodies an intricate system of steps to generate video from still images while maintaining character-specific details. To provide a tangible understanding of its operation, let’s illustrate the process with an example.
Consider a scenario where they aim to animate a character from a still image to perform a dance sequence. The first stage involves encoding the desired pose sequence using our innovative Pose Guider. This encoded pose is then fused with multi-frame noise, a necessary step to introduce the dynamic aspects of movement into an otherwise static reference.
As they proceed, the fused data undergoes a denoising process managed by the Denoising UNet. The UNet contains a computational block consisting of Spatial-Attention, Cross-Attention, and Temporal-Attention mechanisms—a vital triad that ensures the quality of the resultant video creation.
At this point, they integrate crucial features from the reference image in two-fold. First is through the Spatial-Attention mechanism, where detailed features from the reference image are extracted using our specially constructed ReferenceNet. It’s akin to capturing the essence of our character from the given still image. These extracted details then bolster the Spatial-Attention functionality of the UNet, ensuring the preservation of unique elements from the original image.
Secondly, it employs the services of a CLIP image encoder to extract semantic features for the Cross-Attention mechanism. This step makes sure that the broader context and underlying meaning inherent to the reference image are not lost in the animation process.
Meanwhile, the Temporal-Attention mechanism works its magic in the temporal dimension, accounting for the flow of time and seamless transitions necessary for a convincing video output.
Finally, the Variable AutoEncoder (VAE) decoder comes into play, decoding the processed result and successfully converting it into a video clip that has transformed our static character into a dancing figure, alive with motion and retaining its characteristic details.
In sum, ‘Animate Anyone’ method is like a maestro conducting an orchestra, each instrument playing its part in perfect harmony to produce a beautiful symphony—in this case, a dynamic video that breathes life into a still image.
Application and Testing
Discussion of the challenges of providing smooth inter-frame transitions
The challenges of providing smooth inter-frame transitions in character animation are significant. One of the key difficulties is maintaining temporal stability and consistency with detailed information from the character throughout the video. This challenge has been addressed in recent research, which leverages the power of diffusion models and proposes a novel framework tailored for character animation. The proposed framework, called Animate Anyone, aims to preserve consistency of intricate appearance features from a reference image, ensure controllability and continuity, and employ an effective temporal modeling approach to ensure smooth inter-frame transitions between video frames.
The Animate Anyone framework introduces several components to address the challenges of smooth inter-frame transitions in character animation. These components include:
ReferenceNet: This component is designed to merge detail features via spatial attention, allowing the model to capture spatial details of the reference image and integrate them into the denoising process using spatial attention. This helps the model preserve appearance consistency and intricate details from the reference image.
Pose Guider: A lightweight pose guider is devised to efficiently integrate pose control signals into the denoising process, ensuring pose controllability throughout the animation.
Temporal Modeling: The framework introduces a temporal layer to model relationships across multiple frames, preserving high-resolution details in visual quality while simulating a continuous and smooth temporal motion process.
By expanding the training data, the Animate Anyone framework can animate arbitrary characters, yielding superior results in character animation compared to other image-to-video methods. The framework has been evaluated on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
How effective temporal modeling approach addresses the issue?
The effectiveness of the temporal modeling approach in addressing the issue is demonstrated in the context of character animation synthesis. The approach involves the integration of supplementary temporal layers into text-to-image (T2I) models to capture the temporal dependencies among video frames. This design facilitates the transfer of pre-trained image generation capabilities from the base T2I model. The temporal layer is integrated after the spatial-attention and cross-attention components within the Res-Trans block. It involves reshaping the feature map and performing temporal attention, which refers to self-attention along the time dimension. The feature from the temporal layer is then incorporated into the original feature through a residual connection. This design, when applied within the Res-Trans blocks of the denoising UNet, ensures temporal smoothness and continuity of appearance details, obviating the need for intricate motion modeling. Therefore, the temporal modeling approach effectively addresses the issue of temporal smoothness and continuity of appearance details in character animation synthesis.
Video Demo of Animate Anyone
Final Thoughts
The innovative ‘Animate Anyone‘ approach breaks new ground by isolating and animating characters within still images. It echoes the traditional animation workflow, which separates the background from the characters, but brings it into the world of AI. This, in essence, is a pure character animation process. The fact that one can add any desired background behind the animated figure opens a limitless world of creative possibilities.
As we ponder on the future of this technology, curiosity fuels our desire to understand the intricate code that powers it. It’s the mystery behind the scenes, the magic behind the curtain. It’s the complex dance of algorithms that transforms a static image into a lively, animated character.
To say we are impressed by this development would be an understatement. The progress within this field has been astonishing and we find the borders between technology and magic increasingly blurring. The ‘Animate Anyone’ method stands as a testament to the incredible strides we are making in visual generation research. It serves as a beacon, illuminating what’s possible and inspiring us to push those boundaries even further.
We are not only on the edge of innovation – we are actively leaping over it, propelled by the magic of diffusion models, and landing in a world where static images can, truly, come to life. Such is the allure and the power of character animation in the realm of artificial intelligence.
Imagine a world where your computer becomes an extension of your thoughts. A world where you can control every click, every keystroke, and every action without lifting a finger. Introducing the Self-Operating Computer Framework – an open-source tool that gives you unprecedented control over your computer.
With this revolutionary framework, you no longer need to be tied to your mouse and keyboard. Instead, you can harness the power of multimodal models to operate your computer with the same inputs and outputs as a human operator. Just like magic, the model effortlessly views your screen, analyzes the context, and intelligently decides a series of mouse and keyboard actions to achieve your desired objective.
What sets the Self-Operating Computer Framework apart is its compatibility. Designed to work seamlessly with various multimodal models, it offers flexibility and adaptability to suit your specific needs. Currently integrated with the cutting-edge GPT-4v as the default model, the framework boasts unparalleled performance and accuracy.
But that’s not all. This ambitious project has big plans for the future. The Self-Operating Computer Framework aims to support additional models, unlocking even more possibilities and expanding its capabilities beyond imagination.
The Self-Operating Computer Framework
How the framework enables multimodal models to operate the computer.
Multimodal models can operate the computer through the framework by integrating different modes of input, such as text, images, and audio, to understand and generate content. This is typically achieved using a combination of natural language processing, computer vision, and speech recognition techniques. The framework provides a unified architecture for processing and interpreting these different modalities, allowing the model to perform tasks such as generating natural language descriptions of images, answering questions about audio clips, or any other task that requires understanding and generating content from multiple modalities.
Human operator is still essential
While the Self-Operating Computer Framework enables a remarkable level of automation, it’s important to note that the human operator remains an essential part of the process. The framework recognizes the need for human oversight and will regularly prompt you to confirm certain actions, such as hitting the submit button on a form. This ensures that you maintain control over the computer’s operations and can review and verify the actions taken.
It’s worth mentioning that, despite its advanced capabilities, the framework is still in the development stage and may occasionally make mistakes. As it continues to evolve and improve, the aim is to reduce these errors and provide a more stable and reliable experience. Rest assured, the framework values your input and continually strives to work in harmony with the human operator.
Key Features
The Self-Operating Computer Framework boasts an array of key features that make it a force to be reckoned with. First and foremost, its universal compatibility sets it apart from the rest, seamlessly working with a wide range of multimodal models. Whether you’re utilizing text, images, or audio as inputs, this framework can handle it all.
Also, its advanced integration with the powerhouse GPT-4v showcases its commitment to delivering exceptional performance. With GPT-4v as the default model, users can expect unparalleled accuracy and reliability. But the excitement doesn’t stop there. The Self-Operating Computer Framework has ambitious plans for the future, aiming to expand its support for additional cutting-edge models. Get ready to unlock even more possibilities and take your computer experience to new heights.
Examples
The Self-Operating Computer Framework has demonstrated its versatility through various examples. In the repository’s demo, they showcased a task that seemed like a feat of magic: “Go to Google Docs and write a poem about open-source software.” And guess what? The framework accomplished it effortlessly. This remarkable ability to understand complex instructions and execute tasks showcases the immense potential of AI agents in automating everyday computer operations. With the Self-Operating Computer Framework, mundane tasks become a thing of the past, as the model can seamlessly navigate through applications, generate content, and perform actions with incredible efficiency. The possibilities for leveraging AI agents in our daily lives are endless, and this demonstration is just a glimpse into the incredible capabilities that lie ahead.
Closing Thoughts
As technology continues to advance, the potential for AI agents to revolutionize various industries, including software development, is undeniable. The Self-Operating Computer Framework is just one example of how AI agents can transform the way we interact with our computers. With the ability to interpret and execute commands effortlessly, AI agents have the power to streamline processes, enhance productivity, and provide new solutions to complex problems.
One fascinating aspect of the Self-Operating Computer Framework is its compatibility with open-source models. By utilizing open-source models, users can tap into the power of AI without worrying about burning through API requests or facing limitations. This approach democratizes access to AI technology and encourages collaboration within the developer community. The tremendous interest in the Self-Operating Computer Framework, as evidenced by its status as the #1 trending repository on GitHub, highlights the widespread curiosity and excitement surrounding AI-powered solutions.
As we explore the possibilities of AI agents in software development and beyond, it’s important to continue experimenting and testing different approaches. Open-source models provide an avenue for innovation, allowing developers to contribute, improve, and customize the framework according to their specific needs. Through collaboration and the use of open-source models, we can harness the full potential of AI agents and pave the way for a future where the seamless integration of AI technology enhances our daily lives.
The race for superior language AI continues, and Chinese tech giant Alibaba has unleashed a new contender – meet Qwen-72B. As Alibaba’s latest foray into large language models, Qwen-72B represents a massive leap forward with its towering 3 trillion parameters trained on a data mountain of 3 trillion tokens.
Now released as an open source project for all, Qwen-72B blows past previous benchmarks for scale and training. This enormous foundation empowers it to reach new heights in language understanding and generation. Key upgrades include doubling its contextual window to process longer texts as well as enhanced prompt programming for easily customizing for different uses.
Early testing shows this bigger, smarter model already surpassing others in areas like conversational ability, fact recall, summarization and even translation. While researchers continue pushing its paces, Qwen-72B stands poised to expand the frontiers for a new generation of language AIs. For any industry where language interfaces play a key role, more powerful systems like this could soon unlock new potential.
The open-sourcing also comes with a smaller yet still impressive 1.8 billion parameter model available, further expanding access and ability to build specialized implementations. As one of the biggest leaps forward in language AI yet seen, Qwen-72B may spark a new wave of innovation to utilize such immense knowledge and learning capacity.
Qwen-72B Details and Capabilities
Qwen-72B has an expanded context window length and enhanced system prompt capability, allowing users to customize their own AI assistant with just a single prompt. Qwen-1.8B is also released, which strikes a balance between maintaining essential functionalities and maximizing efficiency. It is capable of generating 2K-length text content with just 3GB of GPU memory. The post also mentions the scale of the corpus, which reaches over 3T tokens after deduplication and filtration, encompassing web text, encyclopedias, books, code, mathematics, and various domains.
We can take a look here at their benchmark releases. They selected MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, CMMLU, which are currently popular benchmarks, to test the model’s Chinese and English knowledge capabilities, translation, mathematical reasoning, coding and other capabilities. The benchmark indicates that the Qwen model outperform the similarly sized open-source models on all tasks. But again we have to be wary of benchmarks, since we see this time and time again, they only tell us so much.
Qwen-72B is a large language model with 72 billion parameters, based on the Transformer architecture. It is pretrained on a diverse range of data, including web texts, books, and code, and it has been optimized for performance on various downstream tasks, such as commonsense reasoning, code, and mathematics.
Open Sourcing and Accessibility
The model is completely open sourced under Apache license. he model’s code and checkpoints are open to research purposes and commercial use, and the authors have provided evaluation scripts to help users reproduce the model’s performance.
Final Thoughts
As we reflect on models like Qwen-72B and the rapid progress in language AI, an exciting vision of the future comes into view. With Qwen-72B demonstrating new heights in natural language processing and comprehension, one can’t help but wonder what could be possible by combining these strengths with innovations happening elsewhere.
For example, DeepSeek another open sourced model which was released this week, had profound abilities for programming tasks. One can imagine a future language model that blends Qwen-72B’s language mastery with DeepSeek ‘s coding skills and Constitutional AI’s logical foundations. Such an AI could have the well-rounded intelligence to surpass narrow benchmarks and excel in multifaceted real-world challenges.
The open-source community will play a key role in this future as it enables collaborative innovation between different models and paradigms. With companies like Alibaba open-sourcing their work as well, researchers worldwide can build upon each other’s breakthroughs.
There is still a long path ahead, but the possibilities make the journey exciting. As many push the boundaries – each with their own strengths – we inch closer to broader and more beneficial AI applications. And we look forward to the creative solutions that emerge as these technologies become more accessible.
The future remains promising, and if the recent progress is any indication, this new era of multifaceted and collaborative AI advancement could lead us to profound innovations that make the world a little bit better.
Stability AI has unleashed its most powerful AI yet – introducing SDXL Turbo. Harnessing a groundbreaking new distillation technique, this revolutionary model can generate images of unparalleled quality with just a single step, reducing the required step count from 50 all the way down to one.
Gone are the days of waiting minutes at a time for an AI to slowly refine an image. SDXL Turbo works its magic instantly thanks to an ingenious combination of adversarial training and score distillation, as outlined in the latest research paper.
Eager to experience this imaging turbocharger yourself? Download the open-sourced model weights and code now on Hugging Face and take SDXL Turbo for a spin on Stability AI’s real-time editing platform, Clipdrop. The future of AI image generation is here. Step on the gas and take it for a ride.
SDXL Turbo Details
At the core of SDXL Turbo is a groundbreaking new distillation technique that enables single-step high-quality image generation. To develop this new AI, our research team compared multiple model variants on metrics of prompt relevance and image quality.
The models tested included StyleGAN-T++, OpenMUSE, IF-XL, SDXL, and LCM-XL. Human evaluators were shown two outputs side-by-side and tasked with choosing which one better fit a given prompt and which had higher quality.
In these blind tests, SDXL Turbo beat out a 4-step configuration of state-of-the-art LCM-XL model with just a single processing step. It also surpassed a 50-step configuration of the SDXL model with only 4 steps.
By combining adversarial training and score distillation, SDXL Turbo achieves unprecedented performance, generating images with more photorealistic details and less noise than ever before possible in a single inference pass.
The efficiency gains are massive – reducing computational requirements by over 10x without any drop in quality. This new distillation methodology truly represents a breakthrough in AI image generation.
The details behind this new technique are discussed more deeply in our research paper. But in summary, SDXL Turbo sets a new high bar for fast, high-fidelity text-to-image generation.
Limitations
While SDXL Turbo represents a major leap forward in AI image generation, there are still some limitations to be aware of:
The generated images are a fixed resolution of 512×512 pixels. Higher resolutions are on the roadmap but not yet supported.
Photorealism, while greatly improved, is still not perfect. Some generated images may have minor defects or uncanny elements.
The model cannot render legible text. Any text generated in images will be illegible.
Faces and people may not always generate properly. Results can be inconsistent depending on the prompt.
The autoencoding capabilities are lossy – meaning image edits made in Clipdrop may not be perfectly preserved when regenerating or expanding the image.
For now, being aware of these caveats can help set accurate expectations when exploring the current model’s capabilities.
The rapid pace of advancement in this field gives us confidence that SDXL Turbo is just the beginning. As models continue to improve, so too will the fidelity, control, and flexibility of AI-generated images.
Trying Out SDXL Turbo Yourself
You can try the demo yourself using Clipdrop. Note that you will need an account.
Final Thoughts on SDXL Turbo
The release of SDXL Turbo sparks an interesting debate – is the tradeoff of lower resolution and imperfect photorealism worth the massive speed gains?
It’s true, when compared side-by-side with SDXL, the image quality is diminished slightly. This leaves some questioning if it’s better to wait a minute or two for a higher fidelity 512px image from SDXL vs a fraction of a second for SDXL Turbo’s output.
However, SDXL Turbo enables unprecedented productivity. You can generate hundreds of images, picking only the best ones for upscaling. And with rapid advances in upscalers, starting from a 512px image is less of a hindrance.
The real-time prompting experience is incredibly fast and responsive. And for many applications, having good-enough placeholders to layout a scene or concept is more valuable than a long wait for perfection.
As with any new technology the use cases will evolve over time. There are certainly situations where SDXL’s quality is worth the wait. But for rapid iteration, SDXL Turbo can’t be beat. This newest addition to Stability AI’s lineup expands the creative possibilities, offering both quality and speed to suit varying needs. You can also check out the weights on HuggingFace.
And if the pace of innovation continues, today’s tradeoffs may be eliminated entirely as future models combine the best of both worlds. But for now, SDXL Turbo offers a tempting balance of quality and velocity for AI-assisted art creation.
The field of large language models (LLMs) continues to advance at a rapid pace. The latest development comes with the release of Starling-7B – an open-source 7 billion parameter model that aims to match the performance of commercial models like GPT-4 in most areas, with some key exceptions.
In this post, we’ll take a closer look at Starling-7B, how it was developed, and evaluate its strengths and weaknesses compared to proprietary LLMs. Specifically, we’ll focus on its performance in reasoning, mathematical, and coding tasks.
While Starling-7B represents impressive progress for open-source LLMs, it also highlights areas where further work is needed, especially in domains requiring logical thinking. Nonetheless, the model shows the potential for community-driven efforts to push the boundaries of what’s possible.
Starling-7B Development
The Starling-7B is an open large language model (LLM) developed by a team including Banghua Zhu, Evan Frick, Tianhao Wu, Hanlin Zhu, and Jiantao Jiao. It is trained by Reinforcement Learning from AI Feedback (RLAIF) and is finetuned from the Openchat 3.5 model. The model utilizes the GPT-4 labeled ranking dataset, berkeley-nest/Nectar, and a new reward training and policy tuning pipeline. Starling-7B-alpha has achieved a score of 8.09 in MT Bench with GPT-4 as a judge, outperforming every model to date on MT-Bench except for OpenAI’s GPT-4 and GPT-4 Turbo.
The model is released along with the ranking dataset Nectar, the reward model Starling-RM-7B-alpha, and an online demo in LMSYS Chatbot Arena. The model is licensed for non-commercial use only and is subject to the data distillation License of LLaMA, Terms of Use of the data generated by OpenAI, and Privacy Practices of ShareGPT. The developers express their gratitude to various organizations and the open-source community for their support and contributions to the project.
The Starling-7B is a language model that has been trained using reinforcement learning and has shown impressive performance in MT Bench evaluations. It is part of a larger project that includes the development of a ranking dataset and a reward model. The model is available for non-commercial use and is hosted on HuggingFace.
Starling-7B Performance
The Starling-7B performance is characterized by its ability to beat Openchat 3.5 and come close to GPT-4. It is a reward model trained from Llama2-7B-Chat and fine-tuned on mistral, following the exact chat template and usage as Openchat 3.5. The model’s performance is discussed in various contexts, including comparisons with GPT-4 and other models, as well as issues related to line feed code and prompt templates.
Final Thoughts
The release of Starling-7B represents admirable progress for open-source language models. However, the claim that it “performs almost as well as GPT-4” is likely an overstatement that should be re-evaluated.
I’ve grown wary of claims that tiny models can genuinely compete with or beat GPT-4. Too often, these suggestions stem from benchmarks exaggeration or other questionable practices. While Starling-7B appears to be a legitimate model making strides within its weight class, directly pitting it against GPT-4 triggers skepticism rather than good faith.
Especially concerning is the considerable gap in coding capabilities compared to GPT-4. Code generation requires precise logical thinking – an area still needing improvement in Starling-7B. Additionally, there is no disclosure of the sources of training data – an omission that further raises suspicions.
Rather than sensationalized headlines claiming to beat the leading commercial models, the open-source community would be better served with transparent and realistic assessments. There is impressive work being done, but it does a disservice when the incremental progress is overstated. By maintaining high standards of evaluation and expectation setting, we will build trust and interest in these models for the right reasons.
Thoughts move through our minds like a train – each one connected to the next to form a continuous chain. At times this train speeds efficiently toward a destination, while other times it meanders aimlessly without a clear track. Chain of thought prompting works like a conductor that helps guide this train of ideas by posing thoughtful questions to keep the cars linked and headed in a productive direction. It’s a way of building an agile chain of reasoning by steering our own thought processes. Just as connecting railcars allows the train to cover more conceptual ground, linking each idea to the next can transport our thinking farther than if thoughts merely spurred at random. With practice as the conductor, we can use chain of thought prompting to actively explore topics more deeply and reach new insights. All aboard for this journey to improve reflective reasoning.
The Purpose Behind the Prompts
The goals of using a chain of thought include organizing one’s thinking process, identifying logical connections between ideas, and reaching a well-reasoned conclusion. The benefits of employing a chain of thought include improved problem-solving skills, enhanced critical thinking abilities, and the ability to communicate ideas more effectively.
Constructing the Chains of Questions
Creating effective prompting chains that link ideas can be a valuable skill for various tasks, including brainstorming, problem-solving, and writing. Here are some tips for coming up with effective prompting chains:
Start with a Clear Objective: Clearly define the objective or the main idea you want to explore. This will provide a focus for your prompting chain and help guide the direction of your thoughts.
Use Open-Ended Questions: Begin with open-ended questions that encourage exploration and elaboration. These questions should prompt thinking about different aspects of the main idea and lead to related sub-ideas.
Encourage Divergent Thinking: Prompting chains should encourage divergent thinking, allowing for the generation of multiple ideas and perspectives. Avoid closed-ended questions that limit the scope of exploration.
Link Ideas with Associations: As you progress through the prompting chain, link ideas by finding associations between them. This can be done by identifying similarities, differences, or causal relationships between the ideas.
Explore Different Perspectives: Prompting chains can be more effective when they consider various perspectives. Encourage thinking from different angles, such as emotional, logical, practical, or creative viewpoints.
Use Visual Aids: Consider using visual aids such as mind maps or diagrams to visually represent the prompting chain. This can help in organizing and connecting ideas more effectively.
Iterate and Refine: After generating a series of prompts and linked ideas, iterate through the chain to refine and expand upon the connections. This iterative process can lead to deeper insights and more comprehensive chains.
By following these tips, individuals can develop effective prompting chains that facilitate the exploration and linkage of ideas, leading to richer and more nuanced understanding of the main concept.
Examples in Practice
Source: promptingguide.ai
Prompt 1: What is your favorite subject in school?
Possible Response: I really enjoy math class.
Prompt 2: What about math do you enjoy the most?
Possible Response: I like that there are clear steps to solve problems and get the right answers.
Prompt 3: How do you feel when you get stuck on a hard math problem?
Possible Response: I feel frustrated at first, but I know if I keep trying different strategies I’ll figure it out.
Prompt 4: What strategies do you use when you get stuck?
Possible Response: I go back and double check my work, look at examples from the book, or ask my teacher for a hint.
Prompt 5: When have you used math strategies in your life outside of school?
Possible Response: Well one time I was baking cookies and had to double the recipe – I used fractions to figure out the new measurements.
In this chain, the first question sparks an interest area, then each follow up question builds off the previous response to guide reflective thinking. It explores reasons behind liking math, reactions to challenges, and how math applies more broadly. The prompts aim to keep a continuous flow while uncovering new angles on the initial topic. This helps the speaker think more multidimensionally through chained reasoning.
When Chains Break Down
When the line of thinking gets disrupted, it’s important to take a step back and reassess the situation. Here are some steps to consider:
Pause and Reflect: Take a moment to pause and reflect on the disruption. It’s essential to acknowledge that disruptions are a natural part of the thinking process.
Identify the Disruption: Try to pinpoint the exact cause of the disruption. It could be due to external factors, internal distractions, or a lack of clarity on the topic.
Revisit the Basics: Sometimes, going back to the basics of the topic or problem can help in re-establishing the train of thought. This can provide a fresh perspective and help in overcoming the disruption.
Seek Input from Others: Discussing the problem with a colleague or mentor can often provide new insights and help in overcoming the disruption.
Break Down the Problem: If the disruption is due to a complex problem, breaking it down into smaller, more manageable parts can make it easier to tackle.
Utilize Tools and Techniques: Depending on the nature of the disruption, various tools and techniques such as mind mapping, brainstorming, or visualization can be employed to regain focus.
Take a Break: If the disruption persists, taking a short break can be beneficial. Stepping away from the problem for a while and returning with a fresh mind can often lead to new perspectives.
Remember, disruptions are a normal part of the thinking process, and overcoming them often leads to deeper understanding and insight.
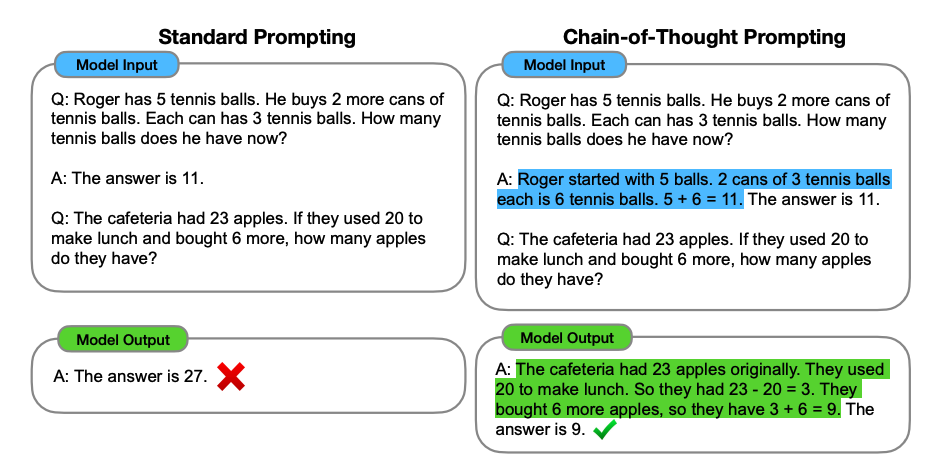
Based on the provided information, the concept of “chain-of-thought prompting” is discussed, which is a method for enhancing reasoning in language models. It involves augmenting each exemplar in few-shot prompting with a chain of thought for an associated answer. The study shows that chain-of-thought prompting is an emergent ability of model scale and enables large language models to solve challenging math problems. It also compares favorably to prior state of the art on various datasets. The study also includes an ablation study with variations of chain-of-thought prompting, such as “equation only” and “variable compute only” prompting.
Proof Chain of Thought Works
This paper provides evidence that chain-of-thought prompting works to elicit reasoning in large language models. The paper “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” explores how generating a chain of thought significantly improves the ability of large language models to perform complex reasoning. The study shows that such reasoning abilities emerge naturally in sufficiently large language models via a simple method called chain-of-thought prompting, where a few chain of thought demonstrations are provided as exemplars in prompting. The experiments on three large language models show that chain-of-thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks. The empirical gains can be striking, with chain-of-thought prompting achieving state-of-the-art accuracy on challenging benchmarks such as the GSM8K benchmark of math word problems.
The study provides empirical evidence that chain-of-thought prompting outperforms standard prompting, sometimes to a striking degree. For instance, on the GSM8K benchmark of math word problems, chain-of-thought prompting with PaLM 540B outperforms standard prompting by a large margin and achieves new state-of-the-art performance. The study also includes an ablation study that explores different variations of prompting, confirming the effectiveness of chain-of-thought prompting in facilitating reasoning in language models.
The evidence from the study supports the effectiveness of chain-of-thought prompting in eliciting reasoning in large language models, particularly for tasks such as arithmetic reasoning, commonsense reasoning, and symbolic manipulation.
Therefore, based on the evidence from the study, there is proof that chain-of-thought prompting works to elicit reasoning in large language models, and the diagrams provided in the paper illustrate how chain-of-thought prompting enables large language models to tackle complex arithmetic, commonsense, and symbolic reasoning tasks.