
February 25, 2025
Scaling Language Models: Why GRPO Could Be the Future
The world of artificial intelligence is being transformed by Large Language Models (LLMs). Reinforcement learning (RL) is a vital learning paradigm for LLMs precisely because it mimics human learning: taking action, receiving feedback, and learning from that feedback to achieve goals.These powerful models are capable of generating human-quality text, translating languages, writing different kinds of creative content, and answering your questions in an informative way. The race to build even bigger and better LLMs is on, promising even more impressive feats of AI.
But there’s a catch. Training these massive models is incredibly expensive. It takes immense amounts of computing power, time, and energy to teach an LLM everything it needs to know. This high cost creates a significant barrier to entry, limiting innovation and potentially leading to an uneven playing field in AI development.
Historical Context of Reinforcement Learning in LLMs
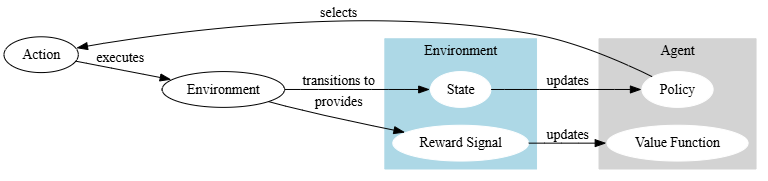
To understand GRPO, it’s helpful to know a bit about how LLMs are typically trained. One common method is called reinforcement learning (RL). Think of it like teaching a dog new tricks. You give the dog a command, and if it performs the action correctly, you reward it with a treat. If it gets it wrong, you don’t give a treat. Over time, the dog learns to associate certain actions with rewards and starts performing those actions more often. Examples of successful RL applications include landmark achievements such as AlphaGo/Zero, which used RL to master complex board games, and Reinforcement Fine-Tuning (RFT), where RL is applied to refine already-trained LLMs.
In the world of LLMs, the “treat” is a mathematical signal that tells the model it’s doing something right. The “commands” are questions or prompts, and the “actions” are the model’s responses. Through countless trials and errors, the LLM gradually learns to generate better and more accurate answers.
Traditional RL methods, such as Proximal Policy Optimization (PPO), have been successfully used to train some impressive LLMs, often used in projects like AlphaGo and deep reinforcement learning. These methods, however, are starting to show their limits when it comes to scaling models, especially as “Scaling laws for reward model over optimization” becomes an issue.
One of the biggest challenges is the need for a separate “critic” model. This critic model is like a second LLM that evaluates the responses of the first model. It’s used to provide a more nuanced reward signal than just a simple “correct” or “incorrect.” But the problem is that the critic model is often just as large and complex as the main model, effectively doubling the computational requirements. DeepSeek-R1, in section 2.2.1 also discusses the need for a “critic” model and references the scaling issues.
This is where GRPO comes in.
How GRPO Addresses Common Training Bottlenecks
GRPO takes a fundamentally different approach to reinforcement learning. Instead of comparing a model’s output to a “perfect” answer or using a separate critic model, GRPO compares multiple outputs from the model to each other. Think of it like this:
Imagine you’re learning to write. Instead of a teacher marking up every single mistake in your first draft (which is what traditional RL methods do), you write several drafts of the same essay. Then, you use a system to help you identify which draft is relatively better, even if none of the drafts are perfect. The system might look for things like better grammar, clearer arguments, or more engaging writing. By comparing your drafts to each other, you can gradually improve your writing skills without needing a perfect example to copy.
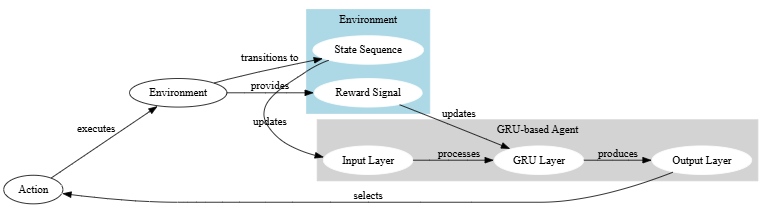
GRPO works in a similar way. It generates a group of different responses to the same prompt and then compares those responses to each other to determine which one is the best relative to the others. This “group comparison” approach avoids the need for a separate critic model, which is GRPO’s key innovation. It was introduced in the DeepSeekMath paper and has since been applied in training models like DeepSeek R1
This also has a large effect on whether we should even use Process Reward Models, PRM, as referenced in “Logic-RL“, a recent paper on RL. The process of explicitly defining a step in general reasoning becomes limited and is no longer conducive.
It also incorporates a KL-divergence, think of this as how “GRPO uses a mathematical tool to measure how ‘different’ the new, improved model is from the original. It wants to encourage improvement, but not too much change, which could lead to instability.” DeepSeek-R1, in section 2.2.1 also references KL divergence. With GRPO’s ability to enhance previously trained data, the author in this blog notes that current fine-tuning methods are primarily imitation learning and suggests offline RL could stitch together historical demonstrations to generate improved solutions, similar to how humans write papers. He also emphasizes the importance of LLMs learning from historical data, even without direct feedback, further cementing GRPO’s potential to change the landscape.
The article “Logic-RL” also discusses how RL and different algorithms have different affects on training and creating potential “shortcuts” for solutions, and also analyzes which words and thinking patterns were most valuable in creating solutions.
Analysis of GRPO’s Scalability Advantages
So, why does GRPO scale better than traditional RL methods? Here are a few key reasons:
- Reduced Computational Cost: By eliminating the need for a separate critic model, GRPO significantly reduces the computational overhead of training LLMs. In some cases, this can roughly halve the computational requirements.
- Faster Training: Because each training step is less computationally expensive, the overall training process can be faster. This allows for quicker iteration and experimentation, leading to more rapid progress in model development.
- Lower Memory Requirements: Since there’s only one model to train, memory usage is reduced. This makes it possible to train larger models or to train models on hardware setups with less memory capacity.
- Simplified Implementation: Avoiding the complexities of managing a separate critic model makes GRPO easier to implement and debug. This may not sound like a huge advantage, but it can make a big difference in the real world, where time and resources are often limited.
- As mentioned in “Logic-RL”, they used a much simpler model to achieve their goals, this hints at GRPO being even more beneficial for more complex ones. This means less data is required.
[images/diagram – Visual representation of resource savings: compute, memory, time]
Resource Optimization Strategies Using GRPO
GRPO’s efficiency also opens up new possibilities for optimizing resource utilization during LLM training:
- Larger Batch Sizes: With lower memory requirements, larger batch sizes can be used. This can lead to more stable and efficient training, as the model sees more examples in each update.
- Distributed Training: GRPO’s efficiency makes it well-suited for distributed training across multiple GPUs or machines. This allows for further acceleration of the training process, making it possible to train even larger models in a reasonable amount of time.
- Experimentation with Larger Models: The reduced resource requirements make it feasible to experiment with even larger LLMs that would be impractical to train with traditional RL methods. This could lead to breakthroughs in model performance and capabilities.
- “Green AI”: Lower computational cost directly translates to lower energy consumption, contributing to more sustainable AI development. As AI becomes increasingly prevalent, it’s crucial to find ways to reduce its environmental impact. Although as the author shares in another experiment that RL training significantly improved a model’s performance on reasoning tasks compared to supervised fine-tuning (SFT), the added RL methods are relatively computationally expensive.
From the findings in “Logic-RL” also notes how better curriculum learning improved all areas of testing. This adds to the possible avenues that are now open due to grpo
Future Potential for Even Larger Language Models
Looking ahead, GRPO has the potential to revolutionize the field of LLM development:
- Beyond Current Limits: Could GRPO be a key to unlocking the next generation of LLMs, surpassing the size and capabilities of current models? It’s certainly a possibility.
- New Architectures: Could GRPO’s efficiency enable the exploration of new model architectures that are currently too computationally expensive to train? This could lead to models that are not only larger but also more efficient and powerful. Currently, achieving longer context lengths is one of GRPO’s biggest challenges.
- Democratizing LLM Development: By reducing resource requirements, GRPO could make large-scale LLM training more accessible to researchers and organizations with limited budgets. This could lead to a more diverse and innovative AI ecosystem.
- Combination with Other Techniques: We can combine GRPO with other optimization techniques to further enhance the performance of the models.
Conclusion
GRPO is a promising new technique that could significantly reduce the cost of training Large Language Models. By offering a more efficient approach to reinforcement learning, GRPO has the potential to unlock the next generation of AI and make LLM development more accessible and sustainable.
While GRPO is still a relatively new technique and further research is needed to fully understand its capabilities, the early results are encouraging. GRPO has the potential to reshape the future of LLM development, paving the way for even more powerful and transformative AI systems.